반응형
이터레이터(iterator)를 잘 다루는 것은 데이터 분석에서 상당히 큰 활용 가치를 가집니다. 단순히 반복문을 효율적으로 돌리는 차원을 넘어서, 메모리 효율성과 속도, 스트리밍 처리, 대규모 데이터 다루기 같은 실무적인 문제 해결에 직접 연결되기 때문입니다.
🔍 왜 이터레이터가 데이터 분석에서 중요한가?
| 항목 | 설명 | 이터레이터 사용 시 장점 |
| 메모리 효율성 | CSV, 로그 파일, 데이터베이스 쿼리 결과는 수십 GB 이상일 수 있음 | readline(), yield, itertools 등을 쓰면 전체를 메모리에 올리지 않아도 처리 가능 |
| 스트리밍 처리 | 실시간 로그, IoT 데이터, Kafka 등 | 이터레이터는 순차적 처리에 최적화되어 있어 스트리밍 분석에 적합 |
| 지연 평가(lazy evaluation) | NumPy, Pandas는 eager, 하지만 큰 데이터에는 lazy 전략이 유리 | map(), filter(), generator expression으로 필요할 때만 계산 가능 |
| 데이터 파이프라인 구성 | ETL이나 전처리 과정에서 단계별 처리 필요 | 이터레이터 체이닝 (예: itertools.chain, map, filter)으로 모듈형 처리 가능 |
| 반복 제어 유연성 | 복잡한 데이터 흐름 제어 가능 | next(), send(), StopIteration 등으로 정교한 제어 가능 |
✅ 실전 예시: 10GB CSV 파일을 행 단위로 처리하기
def process_large_csv(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
next(f) # skip header
for line in f: # 이터레이터처럼 작동
fields = line.strip().split(',')
# 필요한 데이터 전처리
yield fields # lazy evaluation➡️ 전체를 Pandas로 읽으면 메모리 부족 오류
➡️ 이터레이터 + 제너레이터로 메모리 효율 유지하면서 처리
💡 보통 이런 곳에서 쓰입니다:
- map, filter, zip, enumerate 등의 내장 함수
- itertools: 무한 반복, 필터링, 슬라이싱
- Pandas의 DataFrame.iterrows() (이터레이터 방식 제공)
- PySpark RDD, Dask: 이터레이터 기반 분산 처리
- TensorFlow Dataset API도 이터레이터 구조
📚 추천 학습 자료
- David Beazley - Generators: The Final Frontier (PyCon Talk) ← 고급 제너레이터 활용
- Fluent Python (Luciano Ramalho) - 이터레이터와 제너레이터 챕터 강력 추천
✅ 이터레이터를 잘 다루면
👉 메모리 절약 + 속도 향상 + 스트리밍 처리 + 파이프라인 구성
➡️ 데이터 분석, 데이터 엔지니어링, 머신러닝 전처리까지 활용도가 폭넓습니다.
이터레이터를 "for문 대신 쓸 수 있는 것" 정도로 생각하면 안 되고,
**"대규모 데이터 처리의 핵심 전략 도구"**로 봐야 합니다.

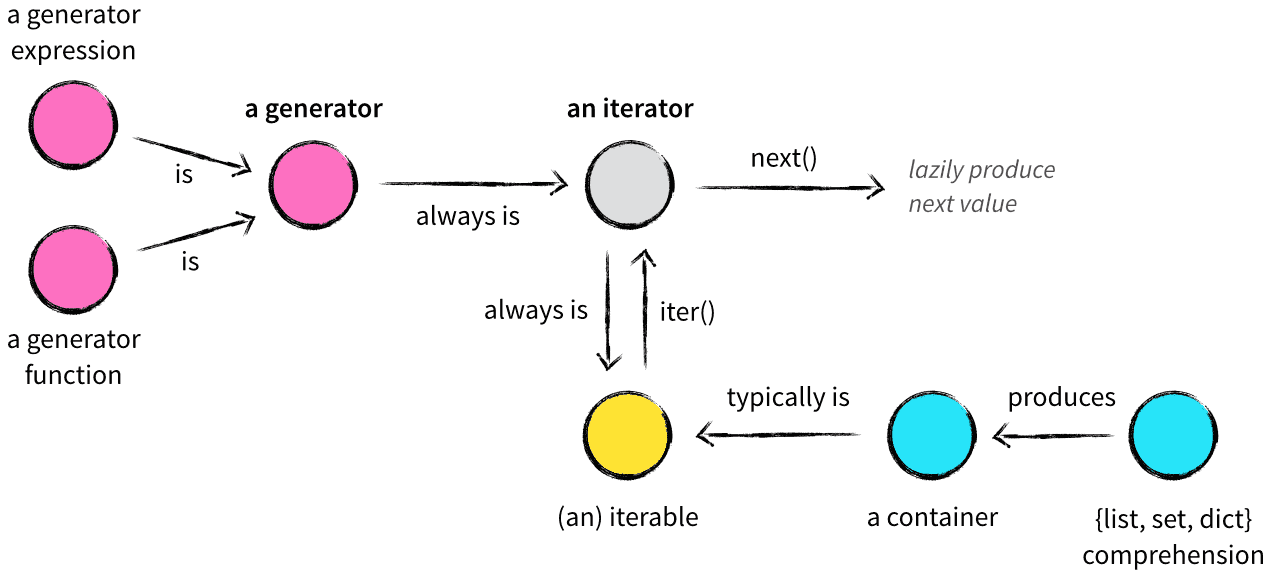
Python의 핵심 개념들: Container, Iterable, Iterator, Generator의 차이를 명쾌하게 설명한 고급 정리입니다.
아래에 윤님이 바로 현장에서 활용할 수 있도록 핵심만 요약해드립니다.
✅ 핵심 요약: 6가지 개념 정리
| 개념 | 설명 | 예시 | 특징 |
| Container | 값들을 담고 있고 in으로 포함 여부 확인 가능 | list, tuple, dict, set, str | 메모리에 전체 자료 보유 |
| Iterable | iter()로 이터레이터를 생성할 수 있는 객체 | list, file, range, socket | __iter__() 메서드 보유 |
| Iterator | next()로 다음 값을 줄 수 있는 상태 저장 객체 | iter(list) 결과, zip(), map() | __iter__()와 __next__() 둘 다 구현 |
| Generator (함수) | yield를 포함한 함수 → lazy iterator | def gen(): yield x | 상태 자동 저장, 반복자 생성기 |
| Generator Expression | (x for x in seq) 형식 | (x*x for x in range(10)) | 메모리 효율적, 반복 가능 |
| Comprehension | list, set, dict에 값을 담는 축약 표현 | [x*x for x in seq], {x: x+1 for x in seq} | 한 번에 메모리 생성 |
✅ 주요 개념 비교
| 개념 | 메모리에 모든 값 있음? | 반복 가능? | next()로 진행? | yield 사용? |
| Container | ✅ | 일부 가능 | ❌ | ❌ |
| Iterable | ❌ 또는 ✅ | ✅ | ❌ | ❌ |
| Iterator | ❌ | ✅ | ✅ | ❌ |
| Generator | ❌ | ✅ | ✅ | ✅ |
🔍 예시 코드 요약
1. Iterable vs Iterator
x = [1, 2, 3] # Iterable
y = iter(x) # Iterator
next(y) # 1
next(y) # 22. Generator 함수
def fib():
a, b = 0, 1
while True:
yield b
a, b = b, a + b3. Generator Expression
def fib():
a, b = 0, 1
while True:
yield b
a, b = b, a + b🔧 핵심 철학
이터레이터는 "값 생산 공장"이고, 제너레이터는 "게으른 공장"이다.
- 매번 next() 호출 때마다 값을 하나씩 생산
- 내부 상태를 유지하며 다음 호출에 이어서 작동
✅ 실무 팁: 코드 변환
# 비효율적인 리스트 수집 코드
def get_items():
result = []
for x in data:
result.append(x)
return result
# 제너레이터로 개선
def get_items():
for x in data:
yield x✨ 요약 정리
- Iterable: 반복 가능한 객체 (__iter__())
- Iterator: 반복 상태를 가진 객체 (__next__())
- Generator: yield를 쓰는 이터레이터
- Generator Expression: ( )로 감싼 리스트 컴프리헨션
Iterables vs. Iterators vs. Generators
https://nvie.com/posts/iterators-vs-generators/
Iterables vs. Iterators vs. Generators
A little pocket reference on iterables, iterators and generators.
nvie.com
반응형
'데이터 분석 > Python 프로그래밍' 카테고리의 다른 글
| 데이터전처리 시계열데이터 기온시각화 pandas csv defaultdict (0) | 2025.07.09 |
|---|---|
| 정규분포 통계 머신러닝 표준정규분포 확률밀도함수 평균 표준편차 시각화 데이터샘플링 히스토그램 (0) | 2025.07.09 |
| .format() 포멧 python 파이썬 print 프린트 (0) | 2025.06.19 |
| 얕은복사 깊은복사 참조변수 사본전달 원본전달 shallow copy deep copy (1) | 2025.06.18 |
| python 파이썬 변수 데이터 타입 확장형for문 pop remove append insert (0) | 2025.06.18 |



